
Using CodeRush Duplicate Code Detection in a Real Project
I’m working on a fairly major refactoring project, merging a couple of fairly large libraries together that have some overlapping/similar functionality. I figured this would be the perfect time to try out the reasonably new CodeRush Duplicate Code Detection feature.
The solution I’m working on has eight projects - four unit test projects, four shipping class libraries, and a total of 1248 C# code files.
I didn’t have duplicate code detection running in the background during the initial pass at the merge. Instead, I ran the detection after the initial pass to indicate some pain points where I need to start looking at combining code. (Let me apologize in advance - I wanted to show you the analysis results in a real life project, but because it’s a real project, I can’t actually show you the code in which we’re detecting duplicates. I can only show you the duplicate reports. With that…)
First, I started with the default settings (analysis level 4):
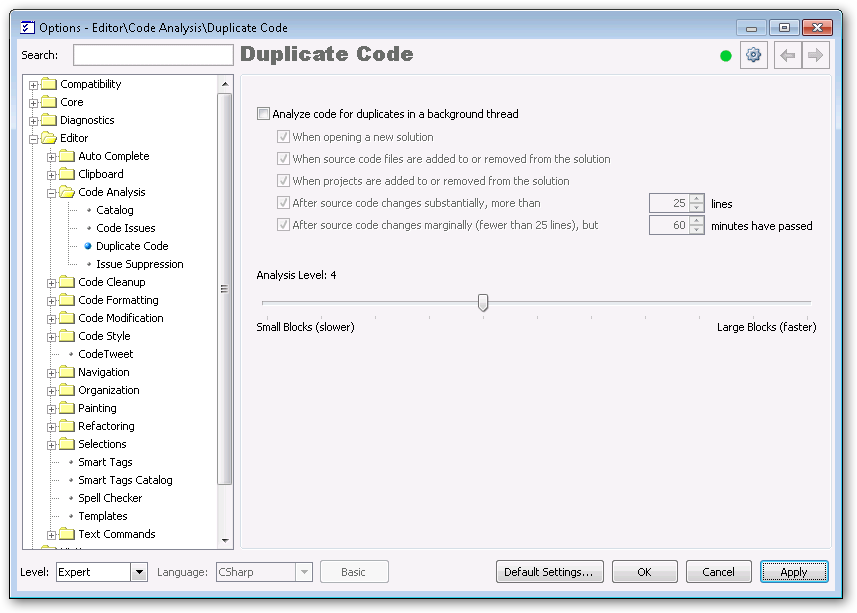
Running that pass took about eight seconds. I found a few duplicate blocks in unit tests, which weren’t unexpected. Things having to do with similar tests (specifically validating some operator overload functionality):
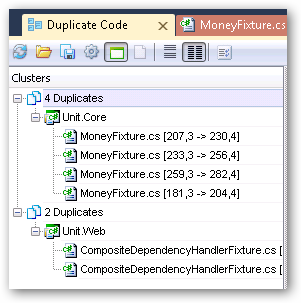
I wanted to do a little more, so I turned it up a notch to analysis level 3 and ran another pass. This time the pass took about 12 seconds and I found a lot more duplicates. This time the duplicates got into the actual shipping code and started pointing out some great places to start refactoring and merging code. This pass also grabbed more duplicates across classes (whereas the previous pass only caught duplicates within a single class/file).
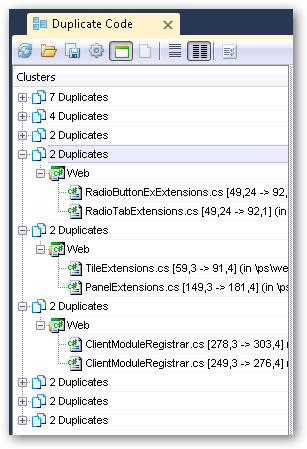
Well, since one notch on the analysis level settings was good, two must be better, right? Let’s crank it up to analysis level 2!
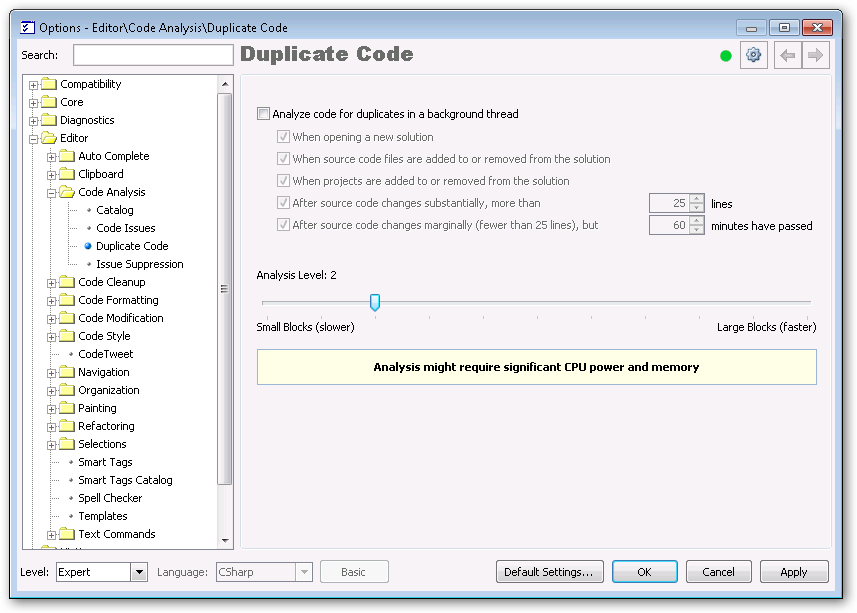
Once you get to level 2 and below, you get a warning: Analysis might require significant CPU power and memory. I’m not too concerned with this right now since I’m running the analysis manually, but if you turn on the background analysis mechanism you’d probably want to verify that’s really what you want.
Anyway, the third pass using analysis level 2 still only took about 12 seconds… and re-running it, to verify that time, only took around 5 seconds so I’m guessing there is some sort of caching in place. (But don’t hold me to that.)
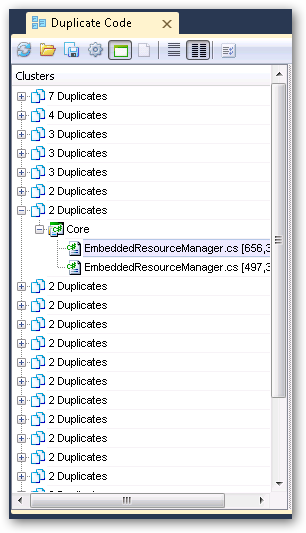
Now we’re talking! Tons of duplicates found on the level 2 run. However, while the code is very similar, there aren’t as many “automatic fixes” that the system can suggest.
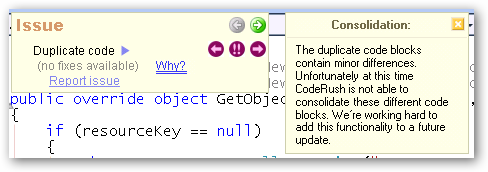
I don’t fault CodeRush for this - the duplicates will require a bit of non-automated thought to combine, which is why they pay us (programmers). (If they could replace us with scripts, they’d do it, right?) I’m sure the geniuses at DevExpress will shortly replace me with a keystroke in CodeRush so they can hire my cat in my place, but until then, I can use this as a checklist of things to look at.
Out of curiosity, I decided to do another run, this time at level 0 - the tightest analysis level available. This run took ~50 seconds and found so many duplicates it’s insane. Some are actionable, some are what I’d call “false positives” (like argument validation blocks - I want the validation to take place in the method being called so the stack trace is correct if there’s an exception thrown). Still, this is good stuff.
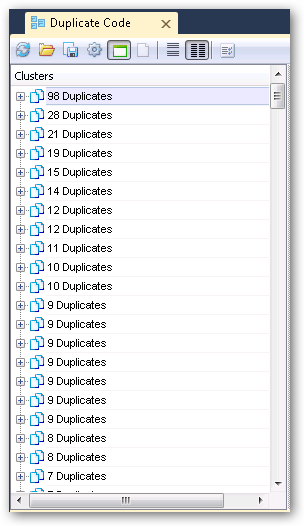
Given the balance between the too-granular detection and the not-granular-enough, I think I’m going to go with the level 2 pass, address those things, and then maybe turn it up from there.
Overall, I was really impressed with the speed of this thing. I mean, 1248 files, thousands of classes… and it takes less than a minute to do super-detailed analysis? That’s akin to magic.
Big props to DevExpress for a super-awesome tool that helps me improve my code. And, hey, some of the automatic fixes that are built in don’t hurt, either. :)
If you want to use this on your project, head over and pick up CodeRush. Honestly, it’s the first thing I install right after Visual Studio, and this sort of feature is exactly why.